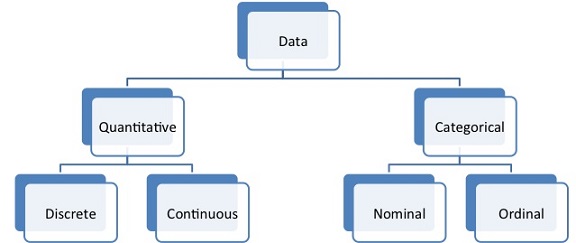
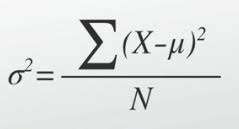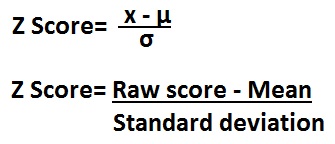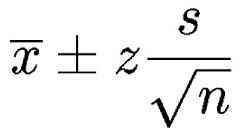the type of data determines the type of statistical analysis used
Categorical Data
data is grouped into categories based on some qualitative trait
Nominal Data
categories are unordered, and no hierarchy is implied
examples include gender, race, nationality
Ordinal Data
order or hierarchy is implied
examples include educational status, severity of illness, cancer stage
Quantitative Data
data is a set of numbers that are counted or measured
Discrete Data
only certain values are possible
represents counted values
examples include test scores, number of operations performed
Continuous Data
data comes from measurements
theoretically, an infinite number of values is possible
examples include age, height, weight, lab values
Data Visualization
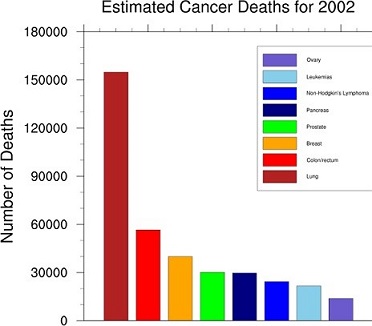
Bar Charts
represents categorical data with rectangular bars with heights or lengths proportional to the values
that they represent
bars can be plotted vertically or horizontally
one axis shows the specific categories being compared
the other axis shows a counted value
usually displayed with gaps between the bars to make it easier to distinguish them from histograms
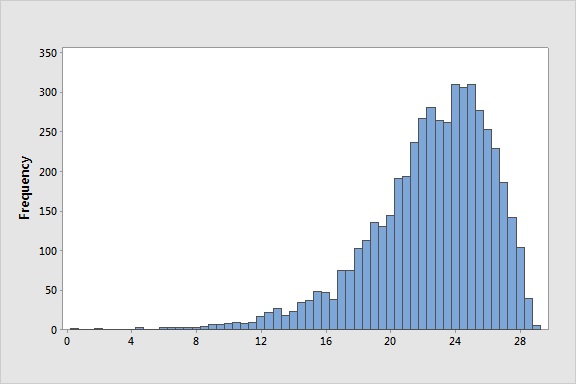
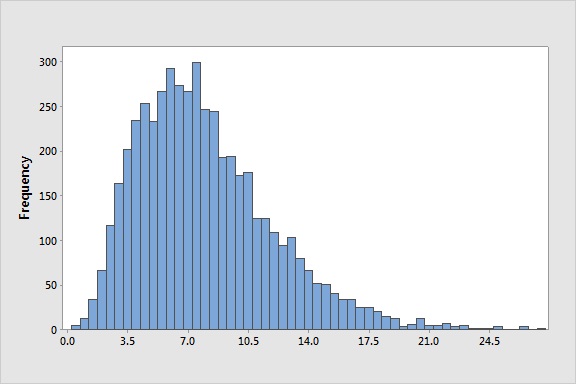
Histograms
represents the distribution of continuous numerical data
the range of values is divided up into a number of buckets or bins
the number of values that fall into each bin is then counted
one dimensional plot (only one variable is being plotted)
there is no best number of bins, and different bin numbers can be used to help reveal different
features of the data
valuable to reveal the ‘shape’ of the data: symmetric, skewed left, skewed right
Top Left: Skewed Left; Top Right: Skewed Right; Bottom: Symmetric
Pie Charts
the arc length (and area) of each slice is proportional to the quantity it represents
shows relative comparisons, not actual values
if some of the pie slices are small, it can be very difficult to compare them
not useful for comparing large amounts of data
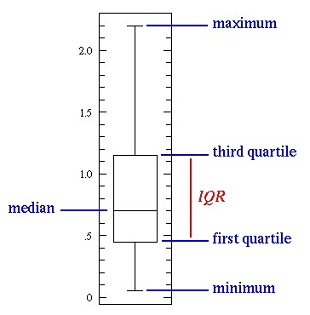
Box Plots
graphically depicts numerical data through their quartiles
the band inside the box represents the 2nd quartile (median)
vertical lines extending from the boxes indicate variability outside the upper and lower quartiles
the ends of the whiskers can represent the minimum and maximum values of the data, or values within
1.5 IQR of the upper and lower quartiles
used when the data is skewed and would not accurately be represented by the mean and standard
deviation
any data not included between the whiskers can be plotted individually as an outlier
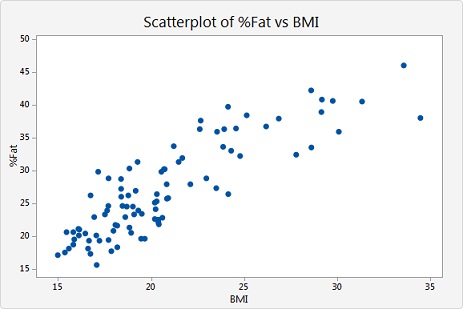
Scatter Plots
displays values for two variables
the dependent, or response, variable is plotted on the y-axis
the independent variable is plotted on the x-axis
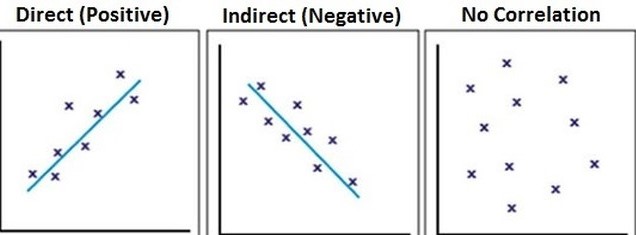
Correlation
scatter plots can be used to see relationships between two variables
when the Y variable tends to increase as the X variable increases, there is a positive
correlation between the variables
when the Y variable tends to decrease as the X variable increases, there is a negative
correlation between the variables
if there is no clear pattern between the 2 variables, then there is no correlation between
the variables
cause and effect is not implied by correlation: there can be many possible explanations
for the patterns seen
Descriptive Statistics
Averages
Mean
central value of a discrete set of numbers (‘balance point’)
calculated by adding up all the values and dividing by the number of values
the population mean (μ) is the mean of the entire underlying population
in medicine, since we are usually sampling from the underlying population, the sample mean
(x̄) is what is calculated
the mean is greatly affected by outliers
Median
separates a data set into two halves – is the middle value
calculation requires the data to be sorted from lowest to highest
much less affected by outlier values than the mean, so it gives a better estimate of a
‘typical’ value
used primarily for skewed data sets
Mode
most frequent value in a data set; i.e. the value most likely to be sampled
used primarily for categorical data
it is possible for a data set to be bimodal or multimodal
Variance and Standard Deviation
used to characterize how wide the spread of the data is from its central point
Variance (σ2)
calculated in several steps:
subtract the sample mean (μ) from each data item (X)
square these differences (converts negative values to positive)
sum up all the squared differences and divide by the number of data items (N)
if using a sampled mean, then divide by N-1
variance is always ≥ 0
since it has units of data2, variance is difficult to interpret
if all the data items have the same value, then the variance is 0
Standard Deviation (σ)
square root of the variance
most common measure of spread since it has the same units as the data
Standard Score (z)
may be positive or negative
represents the number of standard deviations that a data point is above or below the mean
value
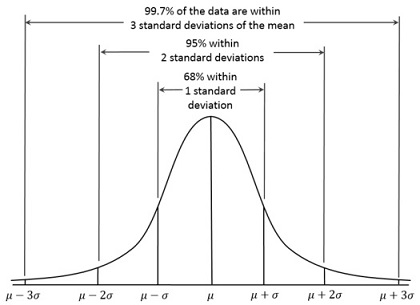
The Normal Distribution
data is distributed around a central value and is symmetrical
mean = median = mode
many processes in medicine follow a normal distribution: height, intelligence, lab tests
in the normal distribution, 68% of values lie within one standard deviation of the mean; 95% of
values are within two standard deviations; 99.7% of values are within 3 standard deviations
in a normally distributed data set, the mean and standard deviation completely describe the data
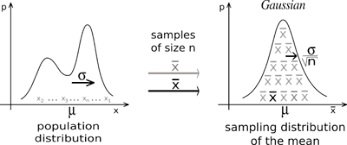
Central Limit Theorem (CLT)
given a sufficiently large sample from a population (≥ 30), the mean of all samples from the
same population will approach the mean of the population
for large samples, the distribution of means calculated from repeated sampling will approach
the normal distribution
the average of all the standard deviations in your samples will equal the standard deviation
in the population
the value of the CLT is that manageable sample sizes can be used to make accurate predictions
about a population
Confidence Intervals
used when making conclusions on samples of data
defines a range of values that we are fairly sure our true value lies in
the sample should contain at least 30 values
need to decide how confident we want to be – in medicine, usually 95% is chosen
using a table, find the ‘Z’ value for the chosen confidence interval
‘Z’ value represents an area under the normal curve and equals the z-score
a small confidence interval = more confidence that our sample mean represents the true mean
as the sample size increases, the confidence interval gets smaller (i.e., we are more confident in
the data)
the value after the ± is called the margin of error
Hypothesis Testing
Null and Alternative Hypotheses
Null Hypothesis (H0)
this hypothesis is assumed to be true until proven otherwise - the status quo
typically represents a value in a population that can be measured
an experimenter is typically trying to produce enough evidence to reject the null hypothesis
Alternative Hypothesis (H1)
research question being answered
null and alternative hypotheses are mutually exclusive
a ‘two-sided’ test is designed to demonstrate that the null hypothesis is not equal
to a certain value
a ‘left-tailed’ test is designed to demonstrate that the null hypothesis is less
than a certain value
a ‘right-sided’ test is designed to demonstrate that the null hypothesis is greater
than a certain value
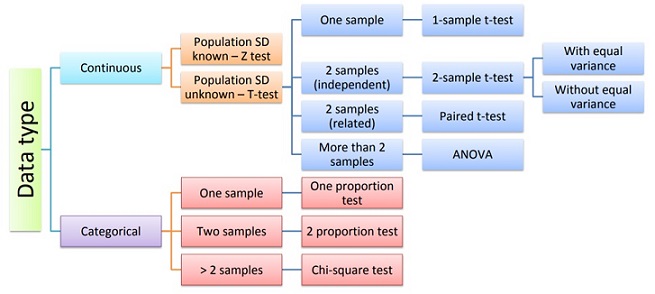
Choose an Appropriate Statistical Test to Analyze the Data
a ‘two-sided’ test is designed to demonstrate that the null hypothesis is not equal to
a certain value
a ‘left-tailed’ test is designed to demonstrate that the null hypothesis is less than
a certain value
a ‘right-sided’ test is designed to demonstrate that the null hypothesis is greater
than a certain value
a t-test is used when the population standard deviation is unknown or for small sample sizes
Set the Significance Level (α)
probability level for making decisions about the null hypothesis
set by the researcher before examining any data
most common level in medicine is 0.05 or 5%
if the test data are inconsistent with the null hypothesis, then the null hypothesis is rejected
Analyze the Test Data
an appropriate experiment must be designed, and data collected and analyzed
a test statistic must be calculated that can be compared to the null hypothesis
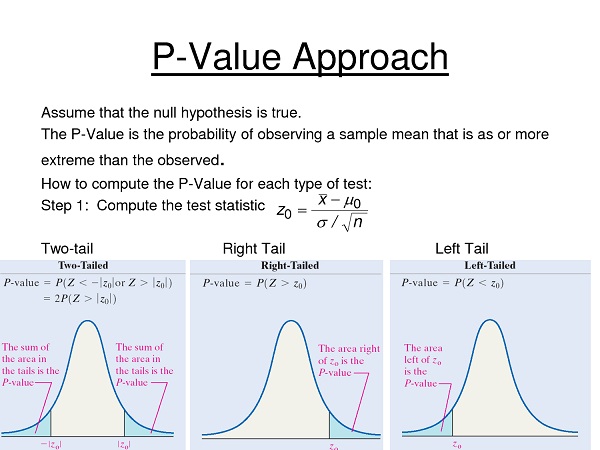
compute the p-value of the test statistic
the smaller the p-value, the stronger the evidence against the null hypothesis
P-Value
is a measure of the strength of the evidence against the null hypothesis
defined as the probability of getting the observed value of the test statistic if
the null hypothesis is actually true
since p-value is a probability, it represents an area under the probability curve
and its value can be looked up in a table or calculated with computer software
the null hypothesis H0 is rejected if p-value ≤ α
Meaning of P-Value
a low p-value is statistically significant, meaning that there is sufficient evidence to
reject the null hypothesis
however, statistically significant not does necessarily mean clinically significant
a low p-value does not tell us how clinically different two treatments are
Error Types
Type I Error (α)
rejection of a true null hypothesis (false positive)
leads one to conclude that an effect exists when it in fact doesn’t
reducing type I errors requires reducing the preset significance level α
reducing type I errors leads to increasing type II errors
confidence level = 1 - α
Type II Error (β)
failure to reject a false null hypothesis (false negative)
related to the statistical power of the test (1 – β)
ways to reduce type II errors include increasing the sample size or relaxing
the α level
Linear Regression
linear approach to modeling the relationship between a dependent (response) variable (y) and one or
more explanatory (predictor) variables (x)
simple linear regression involves only one predictor variable
multiple linear regression involves two or more predictor variables
used for predicting a 'y' value if the 'x' value(s) are known
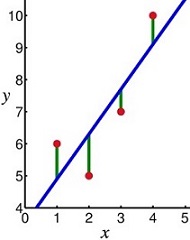
Best Fitting Line
basic idea is to find a line that best fits the data
best fit line minimizes the differences in the ‘y’ direction
linear regression line equation: y = bx + a
a is the y intercept, and x is the slope
Correlation Coefficient (r)
numerical measure of correlation between 2 continuous variables
values range from +1 (strongest positive correlation) to -1 (strongest negative correlation)
R2
proportion of the variance for a dependent variable that is explained by an independent variable or
multiple variables in a regression model